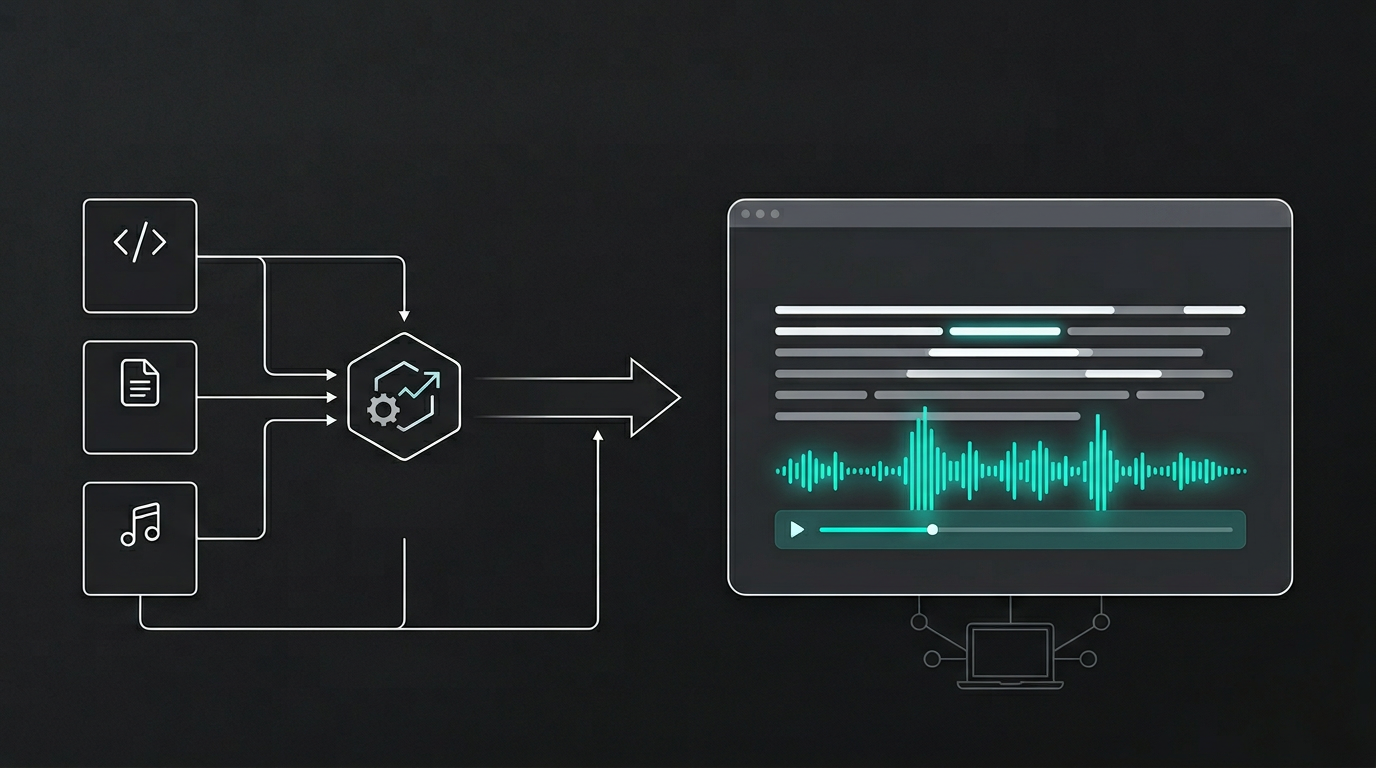
无服务端的跟读音频
网站上的跟读音频通常意味着有一台服务器:用户点播放,服务端跑 TTS、推流,或者至少从数据库里查一条录音。我想在这个站上也有音频——播放按钮和可选的按词高亮——但不加任何运行时。站点保持静态:每页预渲染,CDN 只负责发文件。没有函数调用,生产环境也没有 TTS 用的 API key。
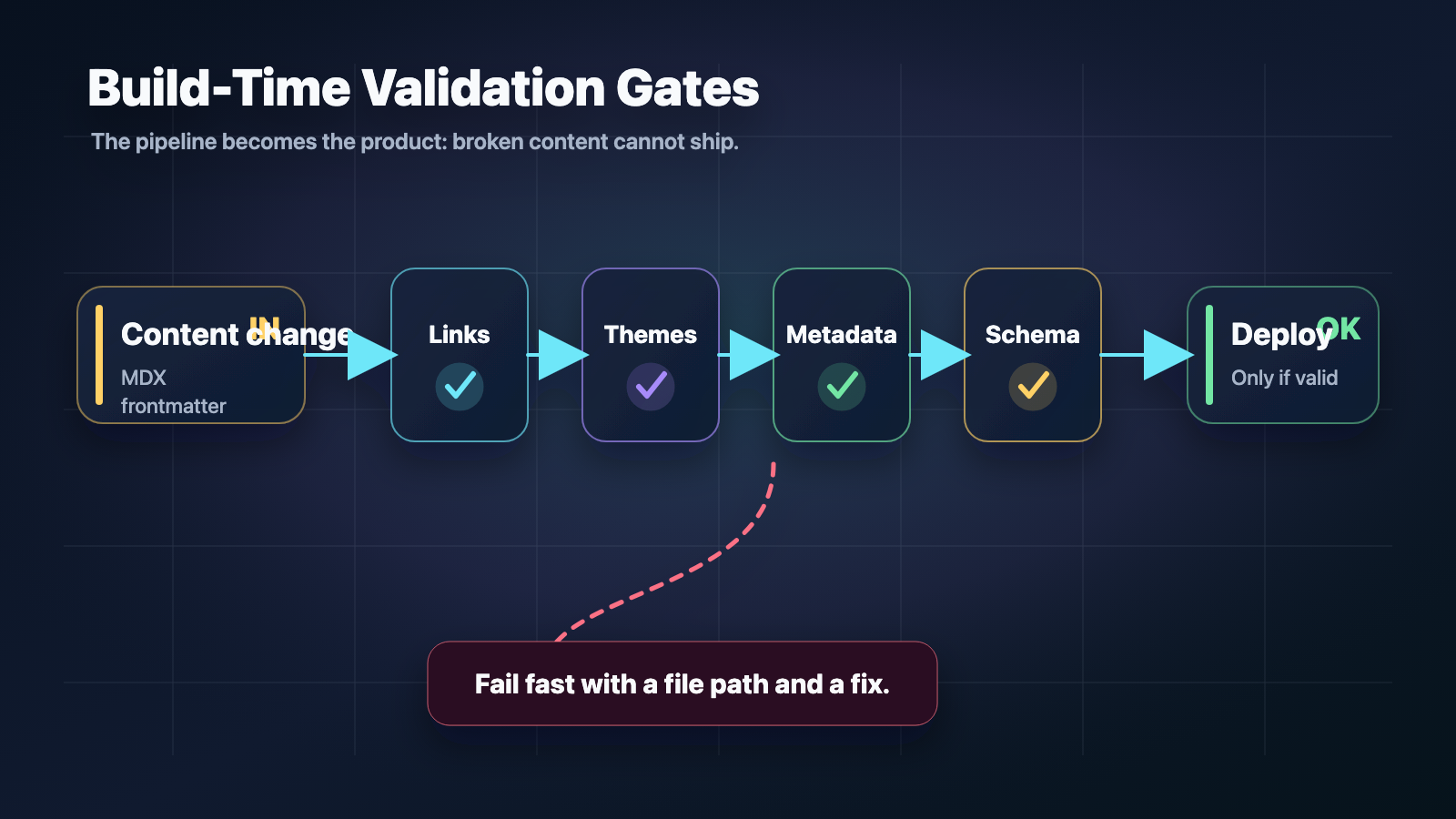
做法是把音频当成构建期产物。内容在构建时已知,音频也可以在构建时生成。生成一次,和别的静态资源放在一起,让静态站去引用就行。不需要服务端。
我是怎么做的
在我想生成音频的时候跑一个脚本——不是每次构建都跑,而是当我新增或改了需要跟读的内容时。脚本读 writing 和 project 的 MDX,把每一篇转成语音和字幕时间轴,写出 MP3 和一个小 JSON manifest,放在 public/audio/ 下。这个目录被 git 忽略。我不把音频提交进仓库;本地生成后,生产环境则上传到公开的 R2 bucket。静态站从不跑 TTS。构建时只需要知道某篇有没有音频以及从哪里取——开发时从 /audio/,生产时从 R2 的 base URL。manifest 驱动这一切。如果某篇不在 manifest 里,页面就按没有播放器来渲染。

开发时我从同源的 /audio/ 提供音频。生产环境设 AUDIO_SOURCE=r2 和 R2_AUDIO_PUBLIC_BASE_URL 指向 bucket 的公开 URL。构建时从该 URL 拉 manifest,把正确的资源 URL 写进每页。你打开文章时,HTML 里已经指好了对应的 MP3 和字幕文件。没有运行时查询。播放器和跟读高亮在「同源」和「从 R2 取」两种情况下行为一致;站点和音频不同源时,唯一要求是给 bucket 配好 CORS,让浏览器能 fetch 字幕 JSON 做高亮。
发布是单独一步。pnpm audio:generate 之后跑 pnpm audio:publish,把 manifest 和音频文件上传到 R2。脚本用 metadata 里的 hash 跳过未改动的对象,所以多次发布成本很低。部署依然简单:把静态产物推到 CDN,保证生产环境有那两条 env 即可。不在 CI 里默认生成音频,生产也不放 TTS 密钥。
静态优先不是少做功能,而是把活放在对的阶段——这里是构建或发布时——再从 edge 把结果送出去。音频在「预生成 + 用 manifest 引用」的前提下完全符合这套模型。