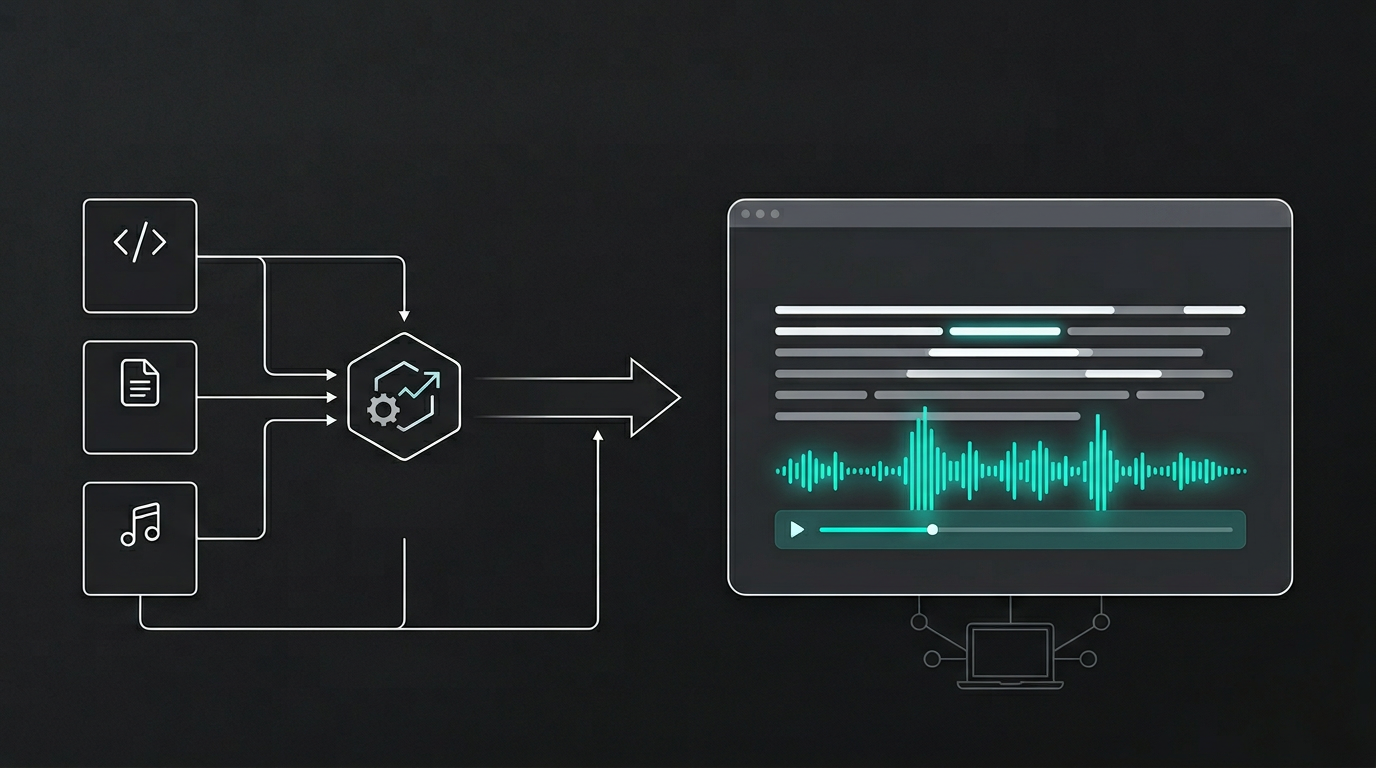
Audio de lectura sin servidor
El audio de lectura en una web suele implicar un servidor: el usuario pulsa play, el servidor ejecuta text-to-speech, hace stream del resultado o al menos consulta una grabación en una base de datos. Yo quería audio en este sitio — un botón de play y opcionalmente resaltado por palabra — sin añadir un runtime. El sitio sigue siendo estático: cada página se pre-renderiza y la CDN sirve archivos. Sin invocaciones de funciones, sin API keys en producción para TTS.
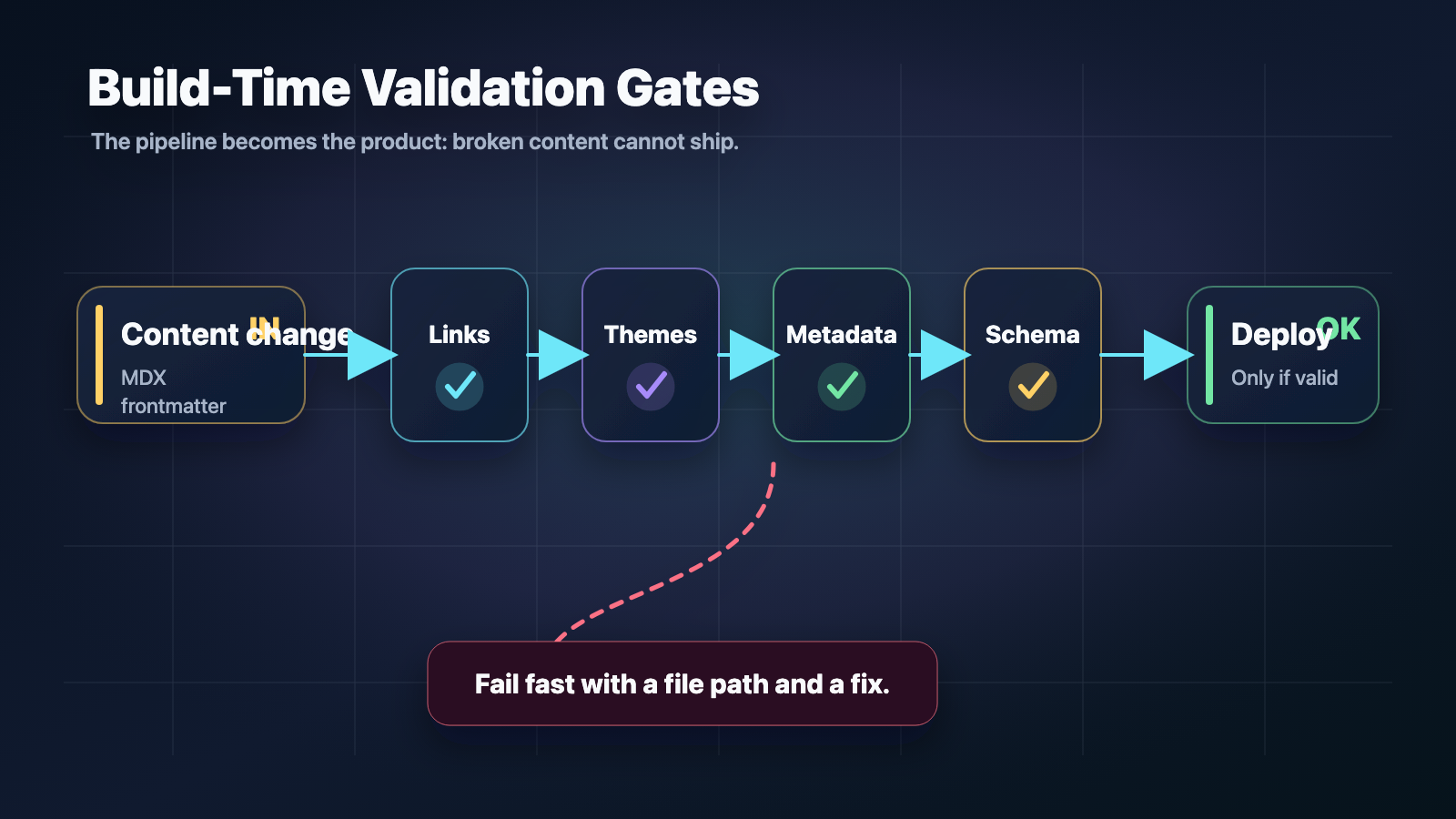
La respuesta es tratar el audio como un artefacto de build time. Si el contenido se conoce en build time, el audio también puede conocerse. Generarlo una vez, guardarlo junto al resto de assets estáticos y que el sitio estático lo referencie. No hace falta servidor.
Cómo lo hago
Un script se ejecuta cuando decido generar audio — no en cada build, sino cuando añado o cambio contenido que debe tener lectura. Lee los MDX de writing y projects, convierte cada uno en voz y tiempos de subtítulos, y escribe MP3s más un manifest JSON pequeño bajo public/audio/. Esa carpeta está en .gitignore. No hago commit del audio; lo genero en local y, para producción, lo subo a un bucket R2 público. El sitio estático nunca ejecuta TTS. En build time solo necesita saber si una entrada tiene audio y dónde encontrarlo — bajo /audio/ en desarrollo o en la URL base de R2 en producción. El manifest lo define. Si una entrada no está en el manifest, la página se renderiza sin reproductor.

En desarrollo sirvo el audio desde /audio/ en el mismo origen. Para producción configuro AUDIO_SOURCE=r2 y R2_AUDIO_PUBLIC_BASE_URL con la URL pública del bucket. El build obtiene el manifest desde esa URL y deja las URLs de los assets correctas en cada página. Cuando cargas un artículo, el HTML ya apunta al MP3 y al archivo de subtítulos correctos. Sin lookup en runtime. El reproductor y el resaltado de lectura funcionan igual si los bytes vienen del mismo servidor o de R2 — el único requisito cuando el sitio y el audio están en orígenes distintos es CORS en el bucket para que el navegador pueda hacer fetch del JSON de subtítulos para el resaltado.
Publicar es un paso aparte. Después de pnpm audio:generate ejecuto pnpm audio:publish, que sube el manifest y los archivos de audio a R2. El script omite objetos sin cambios usando un hash en metadata, así que publicar varias veces es barato. Los deploys siguen siendo simples: subir la salida estática a la CDN y asegurar que el entorno de producción tiene las dos variables de entorno. Sin generación de audio en CI a menos que lo quiera; sin secretos de TTS en producción.
Static-first no significa renunciar a funciones. Significa hacer el trabajo en la fase correcta — aquí, en build o publish time — y servir el resultado desde el edge. El audio encaja en ese modelo cuando se pre-genera y el sitio estático lo referencia mediante un manifest que ya sabe leer.