Read-along audio without a server
Read-along audio on a website usually implies a server. Someone hits play, a server runs text-to-speech, streams the result, or at least looks up a recording in a database. I wanted audio on this site—a play button and optional word-level highlighting—without adding a runtime. The site stays static: every page is pre-rendered, and the CDN serves files. No function invocations, no API keys in production for TTS.
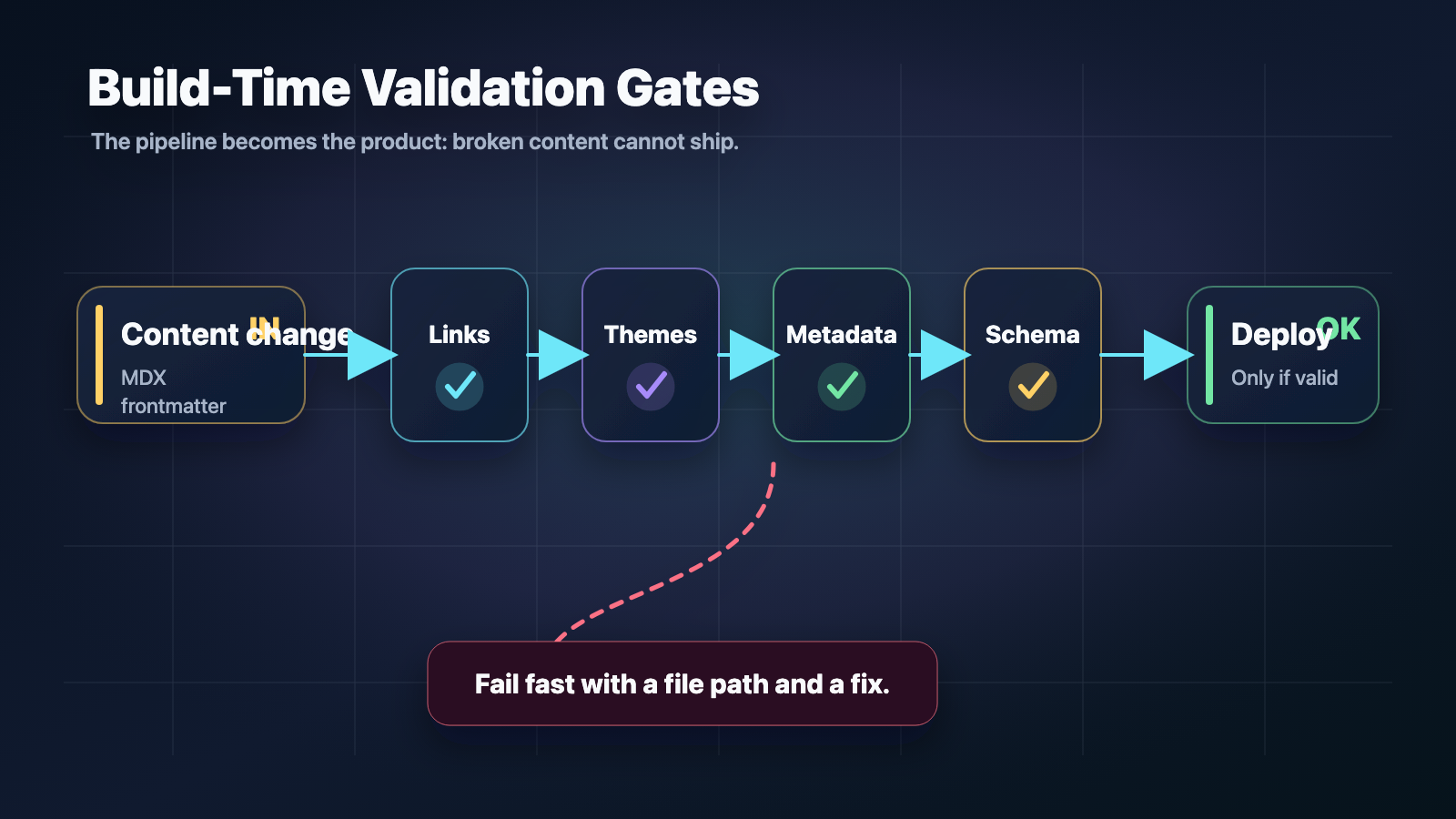
The answer is to treat audio as a build-time artifact. If the content is known at build time, the audio can be too. Generate it once, store it next to the rest of the static assets, and let the static site reference it. No server required.
How I do it
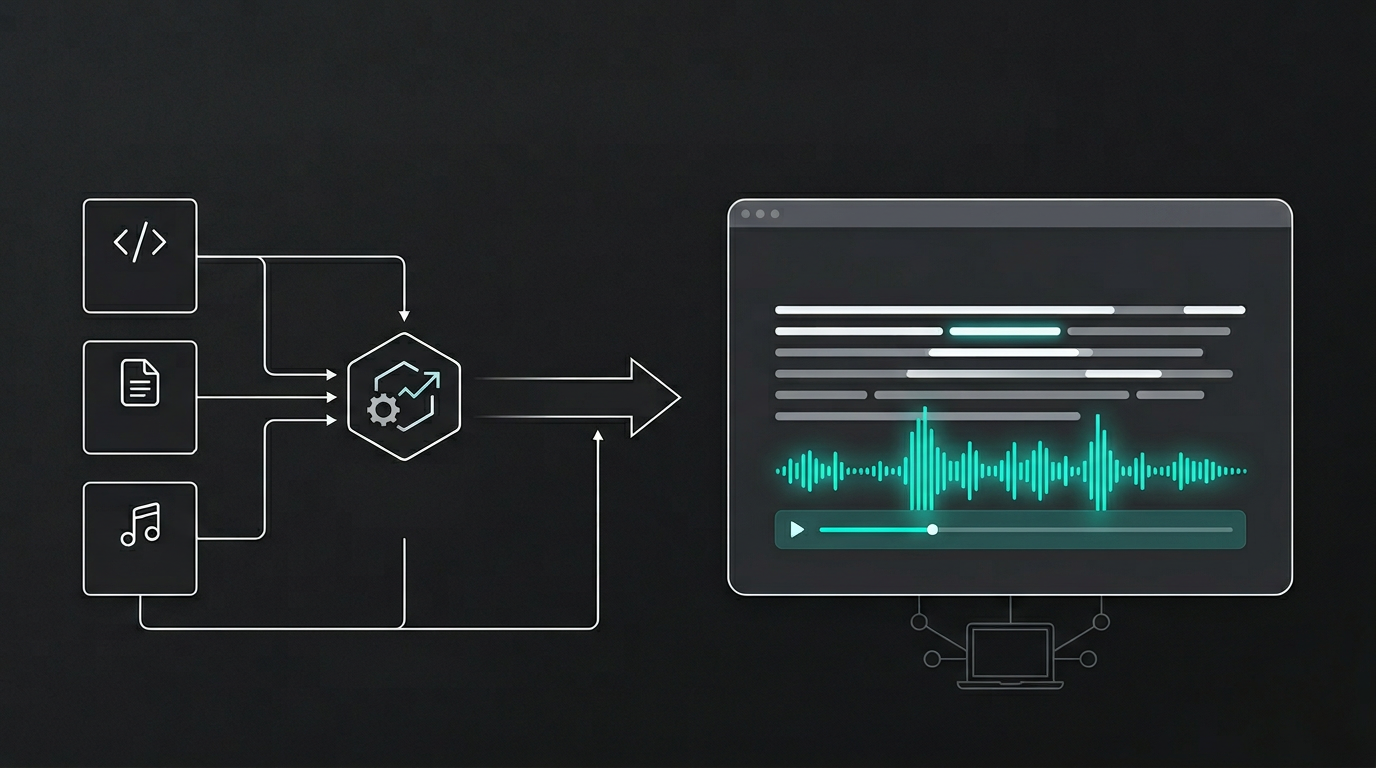
A script runs when I choose to generate audio—not on every build, but when I add or change content that should have a read-along. It reads the writing and project MDX, turns each into speech and subtitle timings, and writes MP3s plus a small JSON manifest under public/audio/. That folder is git-ignored. I don't commit audio; I generate it locally and, for production, upload it to a public R2 bucket. The static site never runs TTS. At build time it only needs to know whether an entry has audio and where to find it—either under /audio/ in development or at the R2 base URL in production. The manifest drives that. If an entry isn't in the manifest, the page renders without a player.

In development I serve audio from /audio/ on the same origin. For production I set AUDIO_SOURCE=r2 and R2_AUDIO_PUBLIC_BASE_URL to the public URL of the bucket. The build fetches the manifest from that URL and bakes the correct asset URLs into each page. When you load an article, the HTML already points at the right MP3 and subtitle file. No runtime lookup. The player and read-along highlighting work the same whether the bytes come from the same server or from R2—the only requirement when the site and audio are on different origins is CORS on the bucket so the browser can fetch the subtitle JSON for highlighting.
Publishing is a separate step. After pnpm audio:generate I run pnpm audio:publish, which uploads the manifest and the audio files to R2. The script skips unchanged objects using a hash in metadata, so repeated publishes are cheap. Deploys stay simple: push static output to the CDN and ensure the production environment has the two env vars. No audio generation in CI unless I want it; no secrets for TTS in production.
Static-first doesn't mean skipping features. It means doing the work at the right phase—here, at build or publish time—and serving the result from the edge. Audio fits that model when it's pre-generated and referenced by a manifest the static site already knows how to read.